


As critical infrastructure across the globe grinds to a halt, StrategicRISK speaks to risk, reputation, data and IT experts to learn what happened, what impacted organisations can do, and steps that risk managers should take to avoid similar crises in the future
Global institutions including banks, airlines, medical institutions, and media outlets are suffering from a major IT outage today, leaving them unable to offer critical services.
Sky News spent the morning unable to broadcast, the US state of Alaska has said that emergency services are impacted, and customers are reporting trouble accessing the National Austalia Bank.
The travel industry has been particularly hard hit, with American Airlines, Delta, and United all issuing a global ground stop on flights. Meanwhile EasyJet, Virgin Australia, and Jetstar have all announced delays.
Airports are impacted too, with Gatwick, Manchester, Schipol, Tokyo, Sydney, Stanstead, and Ediburgh all reporting issues.
In the UK, some GPs are announcing that they can only treat emergencies. One medical centre tweated: “Due to a worldwide IT issue we are unable to access our ckinical system at present. As a result, we can only assess patients who are critically unwell today.” This issue appears to be widespread amongst medical practitioners.
What happened?
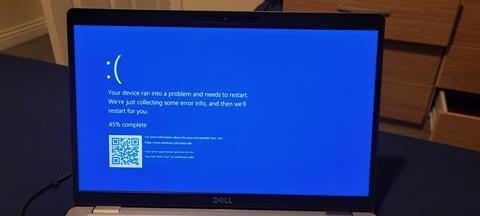
The issue is largely impacting Microsoft users, and is the consequence of an update from third-party security software provider Crowdstrike.
Crowdstrike Falcon is a software that is used mostly for Windows computers that does threat detection.
Bram De Buyser, founder of data and AI consultancy firm Arcology explained the issue: “[Crowdstrike] includes antivirus, but also a lot of other monitoring and invasive stuff to figure out if a machine is vulnerable or even attacked.
“To do that, the software installs drivers. Crowdstrike has pushed an update to one of those drivers, and that update broke it, so now, whenever Windows tries to load that driver it crashes.”
What this means for impacted organisations is that when Windows computers try to load, they encounter the “blue screen of death” (BSOD).
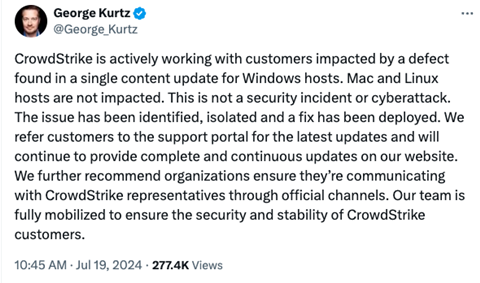
Crowdstrike CEO Geroge Kurtz has confirmed the issue. He said in a tweet: ”CrowdStrike is actively working with customers impacted by a defect found in a single content update for Windows hosts.
“Mac and Linux hosts are not impacted.This is not a security incident or cyberattack.”
Aleksejs Danilenko, head of the IT department at TestDevLab believes that the incident could and should have been avoided.
“While integrating closely with the operating system offers advantages, it also introduces risk. Bugs in CrowdStrike’s code could potentially cause system crashes (BSODs).
“This incident emphasises the critical need for thorough software testing, especially for programs that operate at such a deep level. Rigorous testing in staging environments before deployment is essential to mitigate these risks.”
What can impacted businesses do now?
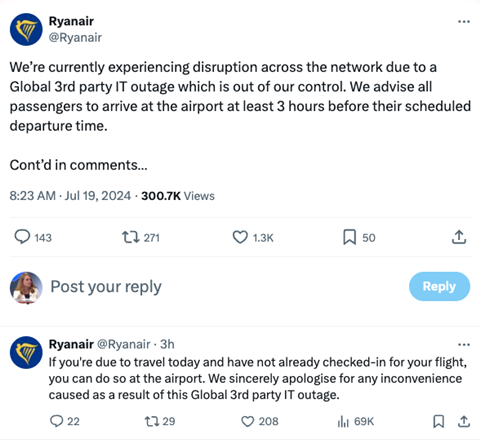
Crowdstrike says that the issue has been identified, isolated and a fix has been deployed.
Kurtz said: “We refer customers to the support portal for the latest updates and will continue to provide complete and continuous updates on our website.
“We further recommend organizations ensure they’re communicating with CrowdStrike representatives through official channels. Our team is fully mobilized to ensure the security and stability of CrowdStrike customers.”
However, experts like De Buyser say that the fix is far from straightforward, and will take time and money to implement. Essentially, businesses need to reboot every impacted machine in safe mode and delete a specific file.
“It’s manual work on every single affected machine. This means delays and insane work costs to get past.”
For companies with tens of thousands of computers, this is time consuming and expensive.
He explains: “It’s manual work on every single affected machine. This means delays and insane work costs to get past. It doesn’t sound like it impacts any data, so there’s no data loss, just time and money.
“It’s going to need to be evaluated in the future whether an invasive threat detection system like Falcon is still worth the risk.
“Ultimately, there’s not much businesses can do about it. Crowdstrike is a pretty solid system, and they’re world leaders for a reason. It’ll take some kind of new software aquisition paradigm to fix this long term, and that’s not likely to happen.”
Organisations should also check their Service Level Agreements (SLAs) and see what they say about downtime. Some businesses may get money back from providers due to the outages, but this is unlikely to come close to the money lost.
However, many SLAs include clauses about viruses, attacks, and acts of God, which may stop firms from receiving any compensation from the outage.
Protecting reputation
Of course, beyond the urgent need to get systems up and running, organisations also need to think carefully about how they communicate with customers.
Regular updates, particularly for consumer-facing organisations are critical. With people unable to access health services, banking, trains, flights, and even the news in some cases, it’s important to ensure that people are up to date.
Tom Lindley, co-founder, and Calum Boal, head of security engineering of Pentesting platform OnSecurity, say: “You might think that suffering a financial loss will be the biggest blow to your company, but a damaged reputation could have an even more significant impact on your business’ future.”
Laura Fox, founder of Canary Risk and IoM Risk Forum chair adds: “It’s not enough to say, “Well, it’s Microsoft/AWS/INSERT OTHER MAJOR SYSTEM, what are we supposed to do when it goes down? It’s outside of our control.”
“A damaged reputation could have an even more significant impact on your business’ future.”
Jonathan Jordan, senior partner, at communications consultancy Sermelo says: “Given the scale of this crisis and its likely impact, which is already being felt across the world, affected organisations will need to use their resources smartly.
“Of course, it will be essential to deploy specialists to tackle the technical issues and get systems back online. But companies also need to dedicate as much resource as possible to connecting with clients and customers to show empathy with the huge challenges they will be facing and the knock-on ramifications of the crisis.
“Organisations which demonstrate they understand the pain of customers and quickly allay fears that its impacts, in terms of costs and inconvenience, will be met, will fare better than those who do otherwise.
“Every crisis presents an opportunity to do the right thing – those who do this quickly and prioritise the needs of their customers will be remembered because actions speak louder than words.”
Looking to the future
Ultimately, experts say that at the heart of this issue is global over-reliance on a few key pieces of software.
Martin Greenfield, CEO, Quod Orbis says: “This incident serves as a reminder that even industry-leading solutions can falter, potentially leaving entire sectors vulnerable.
“The widespread impact of this outage also highlights the interconnectedness of global IT systems and the potential for cascading failures.
“This incident demonstrates how a single point of failure can have far-reaching consequences across multiple sectors and geographies”
However, there are things that businesses can do to protect themselves. Companies must conduct thorough risk assessments, not just of their own systems, but of their entire supply chain and third-party dependencies.
Chair of the IRM’s cyber group, Alex Stezycki says: “This is not the first time an antimalware update has caused such an issue, which is why companies should have testing regimes in place for all software updates.
“This incident demonstrates how a single point of failure can have far-reaching consequences across multiple sectors and geographies”
“Admittedly, this is easier said than done, but by having a subset of your compute restate accept an update first an issue could be identified before it reaches critical systems that impact critical business operations.
“It is however essential that organisations continue to run, update and patch their ICT infrastructure to mitigate the far greater risks of external cyber threat actors”.
De Buyser agrees, adding: “Good IT practice would involve disabling automatic updates and doing gated updates, but that’s slow, costly to do, and comes with its own risks.
“More systems should be airgapped - disconnected from any other networks - to stop threats including bad updates but that’s not always possible or reasonable.”
Organisations must also adopt a more holistic approach to their cyber resilience, implementing a multi-layered defence strategy that encompasses not just software solutions, but also robust policies, regular training, and proactive threat hunting.
Greenfield says: “A key component of this approach should be continuous controls monitoring, which allows for real-time visibility into the effectiveness of security measures and rapid response to emerging threats.”
Better business continuity planning
Stezycki says that organisations should also have practiced business continuity plans in place to ensure they are resilient to computer/power/act of God events to manage the risk of such outages.
Fox agrees, stating that today’s Microsoft outages serve as a crucial reminder for operations to reassess what business continuity looks like during a major system outage.
Such incidents often go undocumented, dismissed as a “very unlikely/high impact risk” (what she calls the top left corner of doom on a risk matrix).
She advises that busineses must document the impact of these outages in a business impact assessment, detailing their effects on your business, including stakeholders like your client base and regulatory bodies if applicable.
“The best risk and resilience teams will have prepared their businesses for such outages.”
Firms must then determine what’s acceptable, what’s unacceptable, and what actions you’ll take if such an event occurs.
Operational Resilience regulations, such as DORA, expect the impact of such outages to be documented. This includes having scenarios and continuity plans in place.
Fox concludes: “The best risk and resilience teams will have prepared their businesses for such outages. IT teams can then focus on fixing the issues with the support of a well-thought-out plan.
“Does this mean all problems are solved and there are no impacts? Absolutely not. But the operational impact on businesses that are well-prepared and have invested in resilience is likely far lower.”










No comments yet